python爬虫:使用xpath基础+实例 |
您所在的位置:网站首页 › xpath 的用法 › python爬虫:使用xpath基础+实例 |
python爬虫:使用xpath基础+实例
|
目录 一、Xpath (一)简介 (二)基本用法 1.原理 2.导入模块并实例化 3.书写Xpath表达式 / * text() 注意的几个点: @ 二、实例 (一)流程 编辑(二)补充 (三)过程中一些值得记录的处理 三、代码 大佬博客写得很好,看视频学习过程中跟着这个思路做了总结,自己也跟着做了一个实例:Python爬虫实战之xpath解析_python xpath_阿浩( ̄▽ ̄)的博客-CSDN博客 一、Xpath (一)简介Xpath 是高效简单,在XML文档中搜索内容的一门语言,最初是用来搜寻 XML 文档的,但是HTML语言是XML的一个子集,它同样适用于 HTML 文档的搜索。 在Python爬虫中,我们经常通过安装 lxml 库,利用 xpath 解析这种高效便捷的方式来提取信息。 (二)基本用法 1.原理
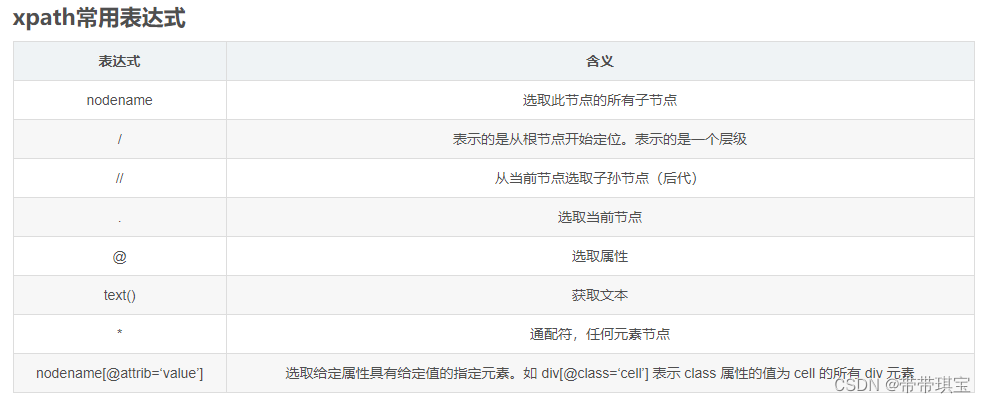
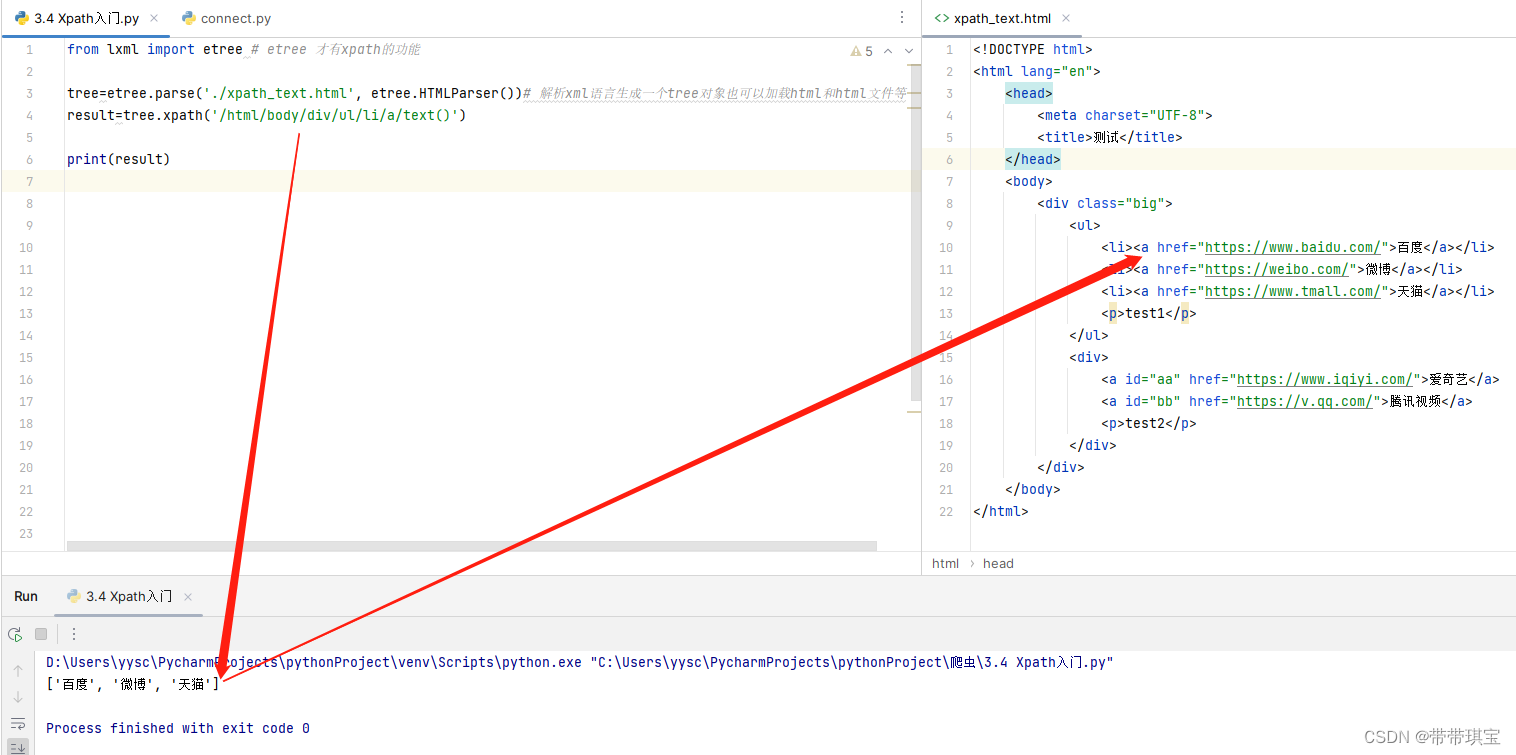
模拟一段网页源码进行测试: 测试 百度 微博 天猫test1 爱奇艺 腾讯视频test2 该源码中,称每个标签为“节点”,节点与节点之间存在父子关系或兄弟关系,Xpath 原理就是可以通过节点之间的关系查找定位想要的节点(类似电脑里面的文件路径) 2.导入模块并实例化(1) 需要导入 lxm 中的 etree 模块,这个 etree 就具有 xpath 的功能 from lxml import etree(2) 实例化 通过实例化一个 etree 得到实例对象,且需要将被解析的页面源码数据加载到该对象中。有两种方式: ①从本地的html文件加载: tree=etree.parse('本地的html文件路径',etree.HTMLParser()) # 要指定文件的类型,这里是 etree.HTMLParser(),否则出现报错②将获得的网页源码加载: tree=etree.XML('网页源码') # 或者 tree=etree.HTML('网页源码') 3.书写Xpath表达式实例化得到对象后,就能用 .xpath 方法取标签、属性、标签标记的值了 /通过/可以取到节点(即某路径下的标签),可以用 ./ 在当前节点开始使用相对路径开始查找 result=tree.xpath('/html/body/div/ul/li') print(result)结果:
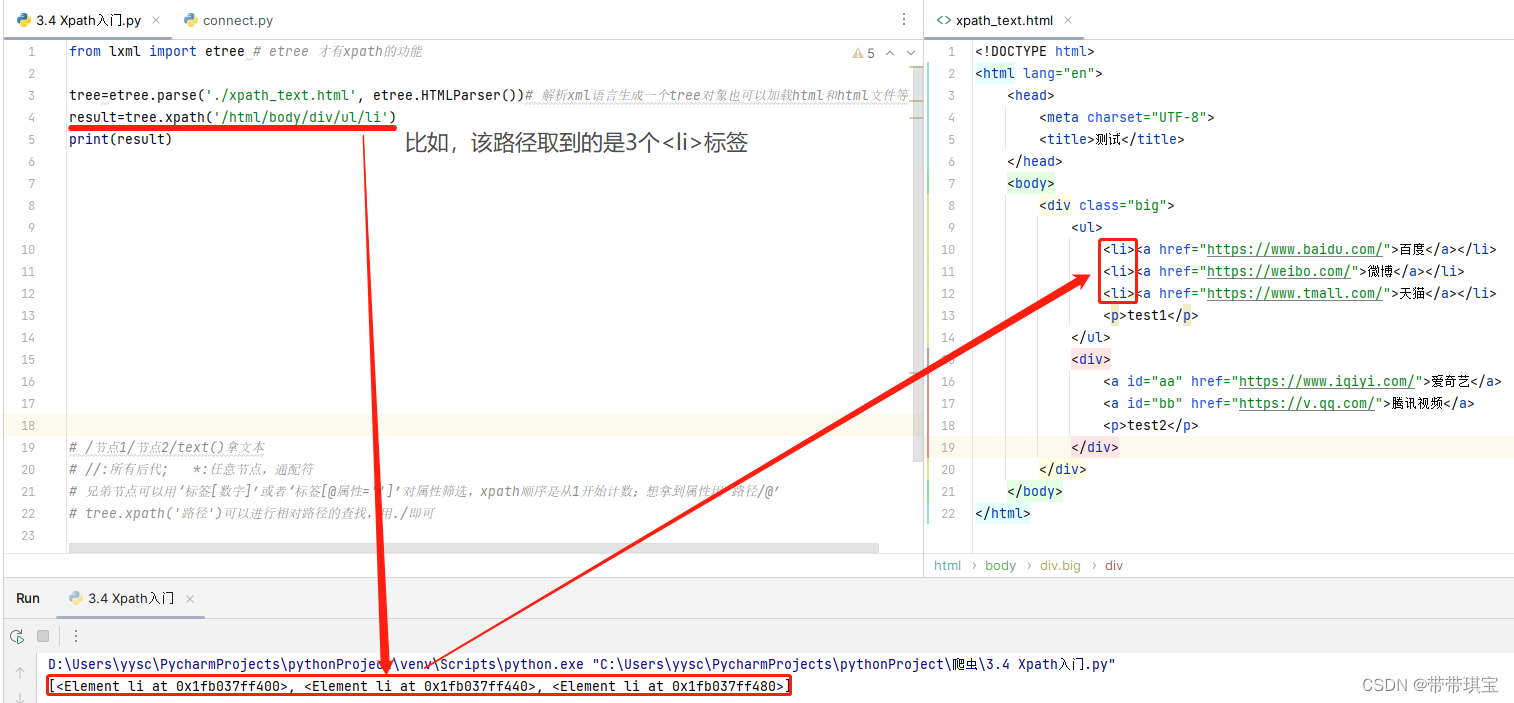
// 取其他节点同理,但观察源码发现在里面,节点很多 存在于不同的父节点下,我们想用这种方法同时取到节点,使用//表示某个父节点的所有后代即可 result=tree.xpath('/html/body/div//a') print(result)
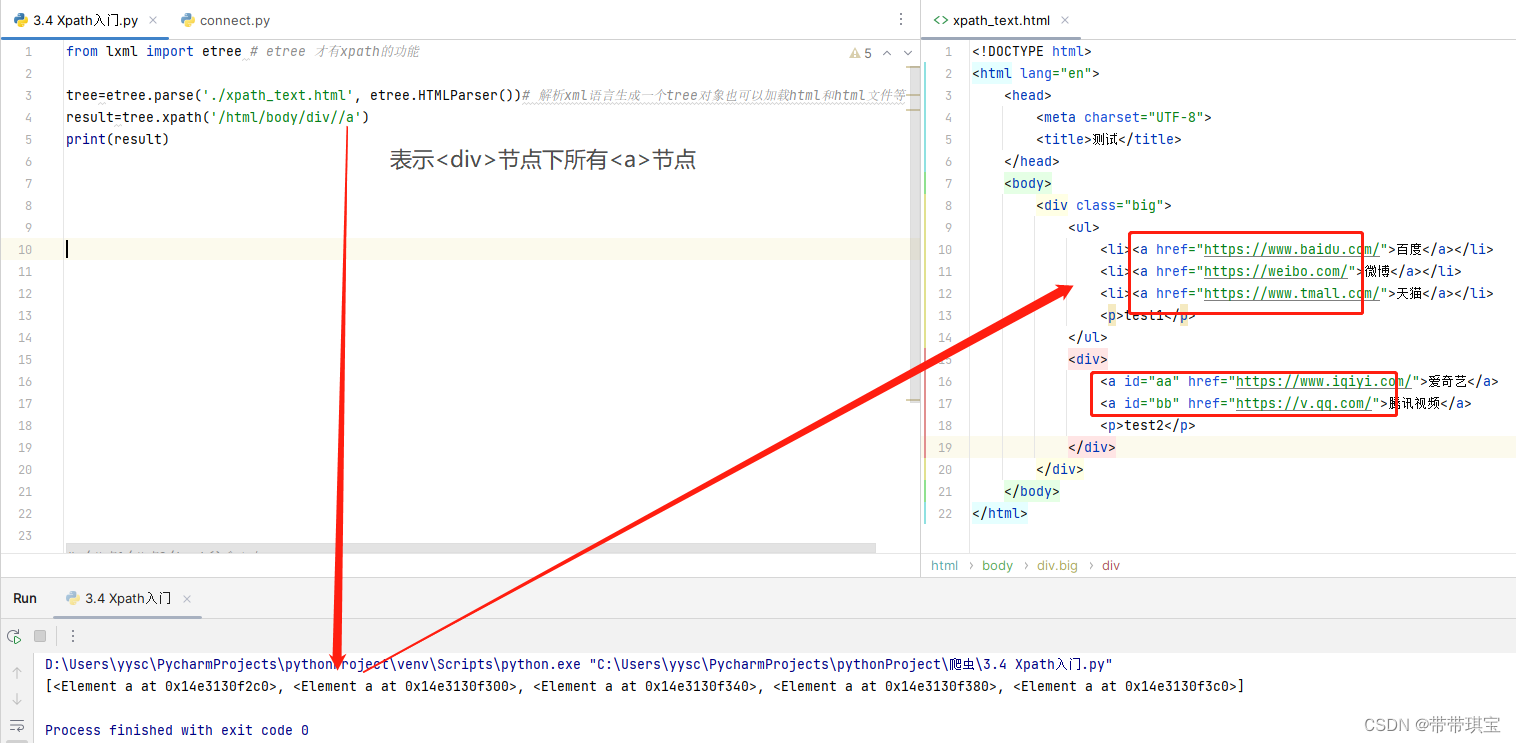
源码中的一个节点 有着相同的层级关系:只是其父节点不同,通配符可用来表示任意节点,自然可以表示他们的父节点了 result=tree.xpath('/html/body/div/*/p') # 两个路径分别为: # '/html/body/div/ul/p' # '/html/body/div/div/p' print(result)
text()用于获取标签所标记的文本 result=tree.xpath('/html/head/title/text()') print(result)
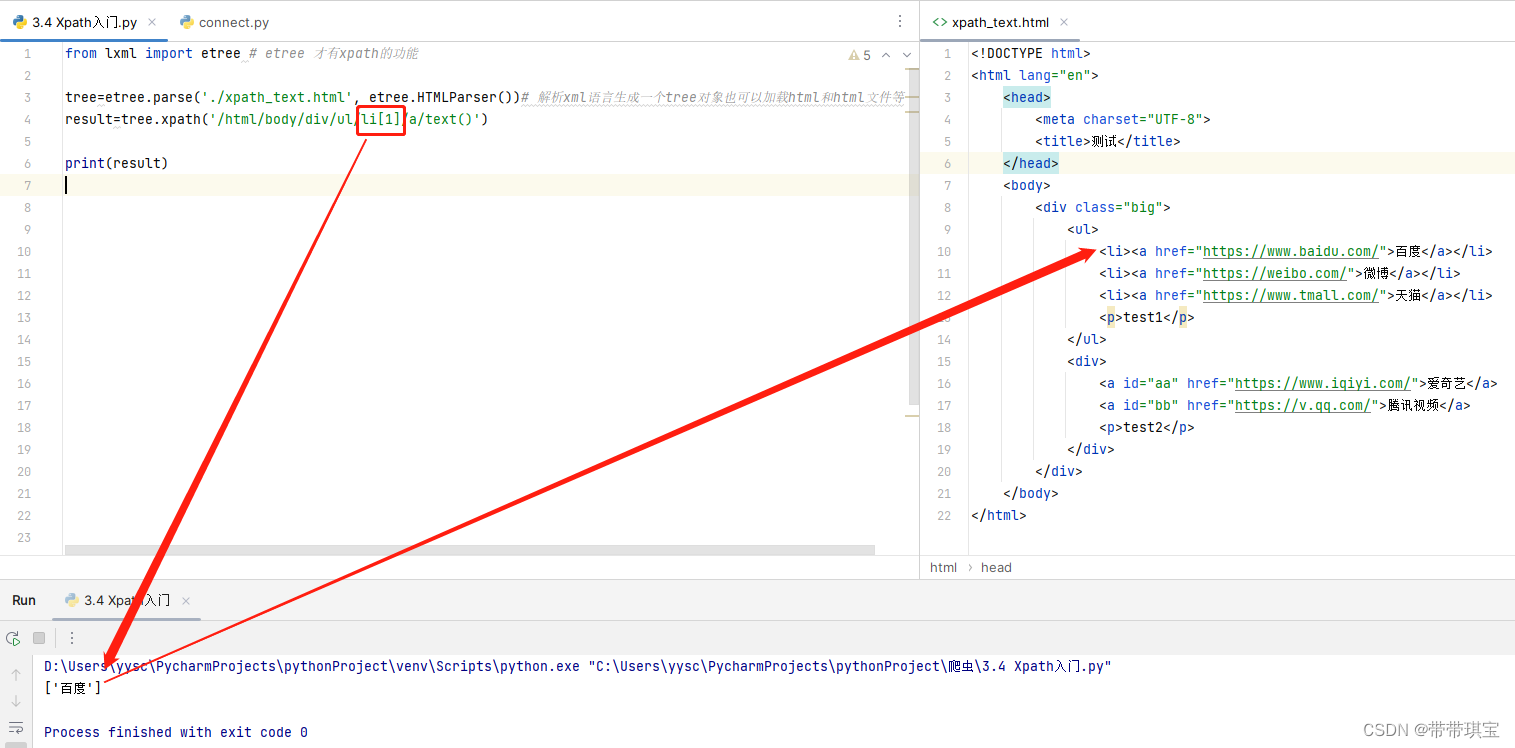
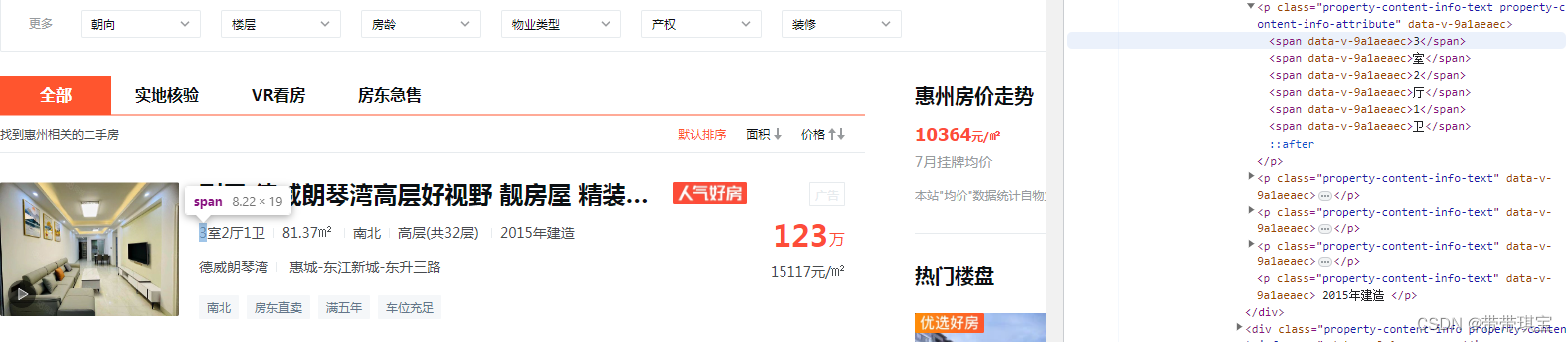
这样子我们取到该路径下的所有标签,如果只想取到第一个值,可以通过索引或者来取 result=tree.xpath('/html/body/div/ul/li[1]/a/text()') print(result) 注意的几个点:1.因为是从开始有三个的, 这里不能对text()或索引,如果对索引,依然会把所有筛选出来 2.xpath顺序是从1开始计数 3.注意返回的结果是一个列表,如果想得到字符串还要进一步选取 4.如果标签有属性,也可以通过'标签[@属性='']'的方法筛选获得文本内容
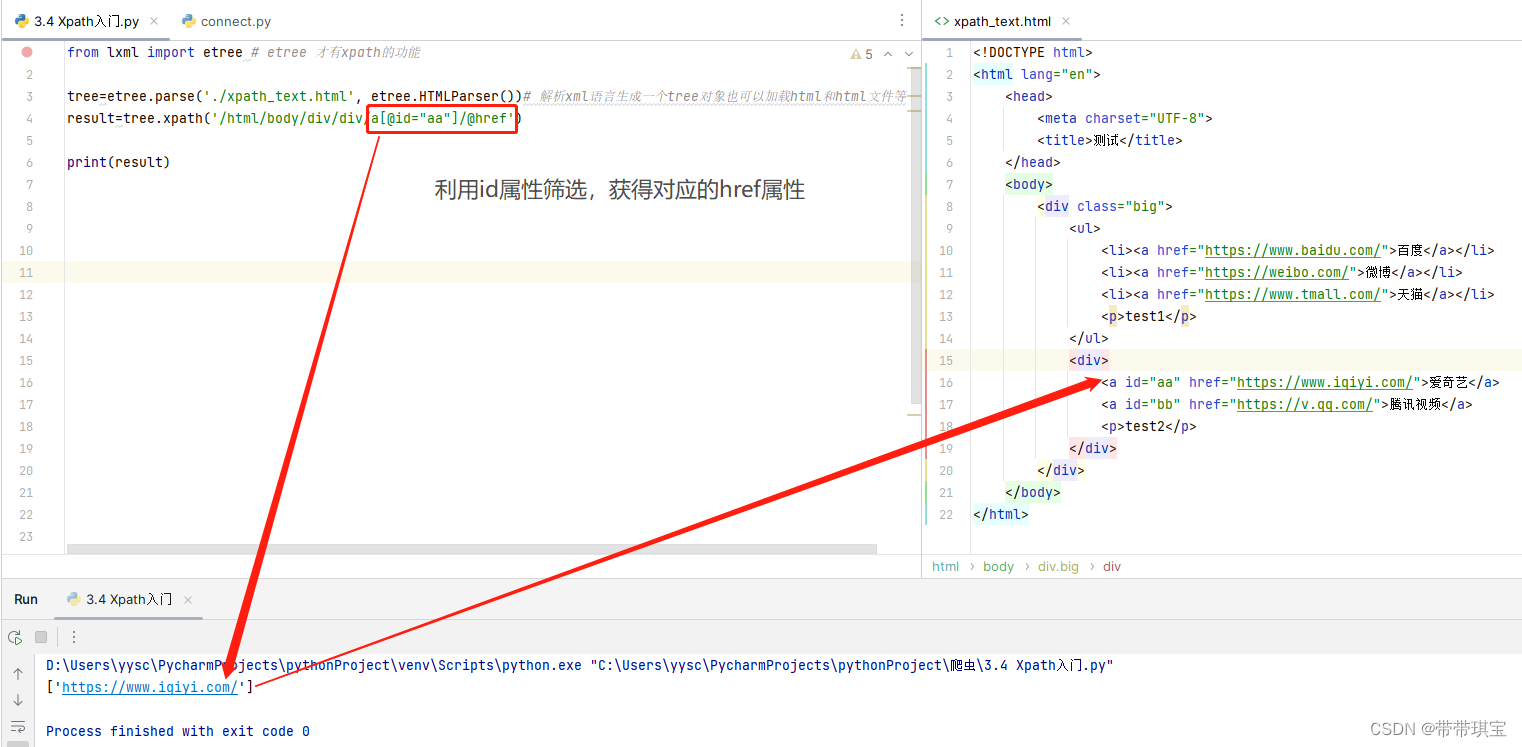
在网页源码里可能会把图片链接放在标签的属性中,因此有时候我们也会需要获取标签的属性,@的功能就是定位标签或者得到标签的属性,用法如下: 想要获得爱奇艺的链接,可以根据 id 属性定位
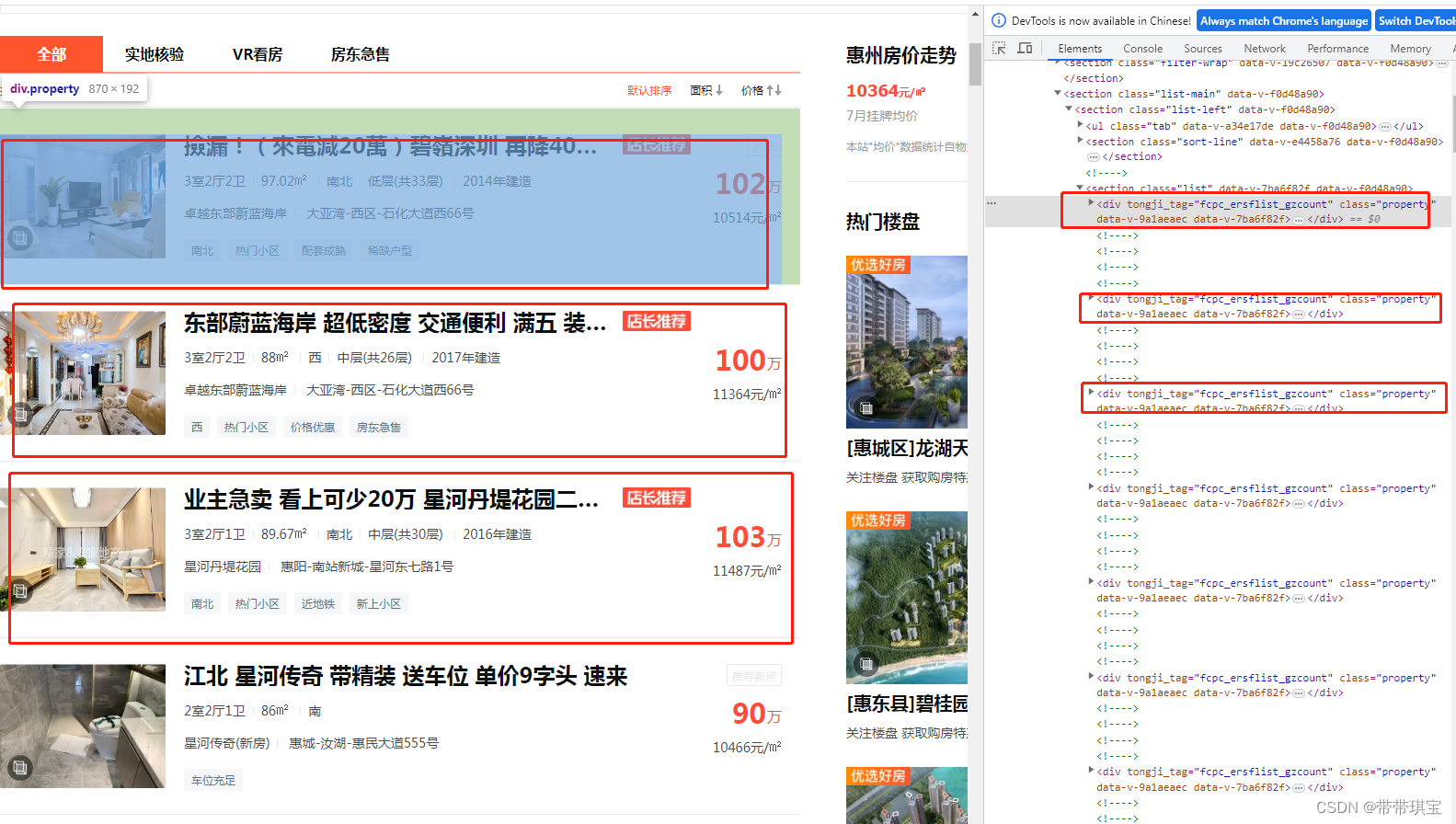
以上是Xpath的基本用法,关于更多移步博主Python爬虫实战之xpath解析_python xpath_阿浩( ̄▽ ̄)的博客-CSDN博客 这里给自己提醒一下,切记右键查看网页源代码: 我们看到这些并列的项代表着一个个房源的信息,在这里面取到想要的数据后可以通过循环可以获得多个房源信息
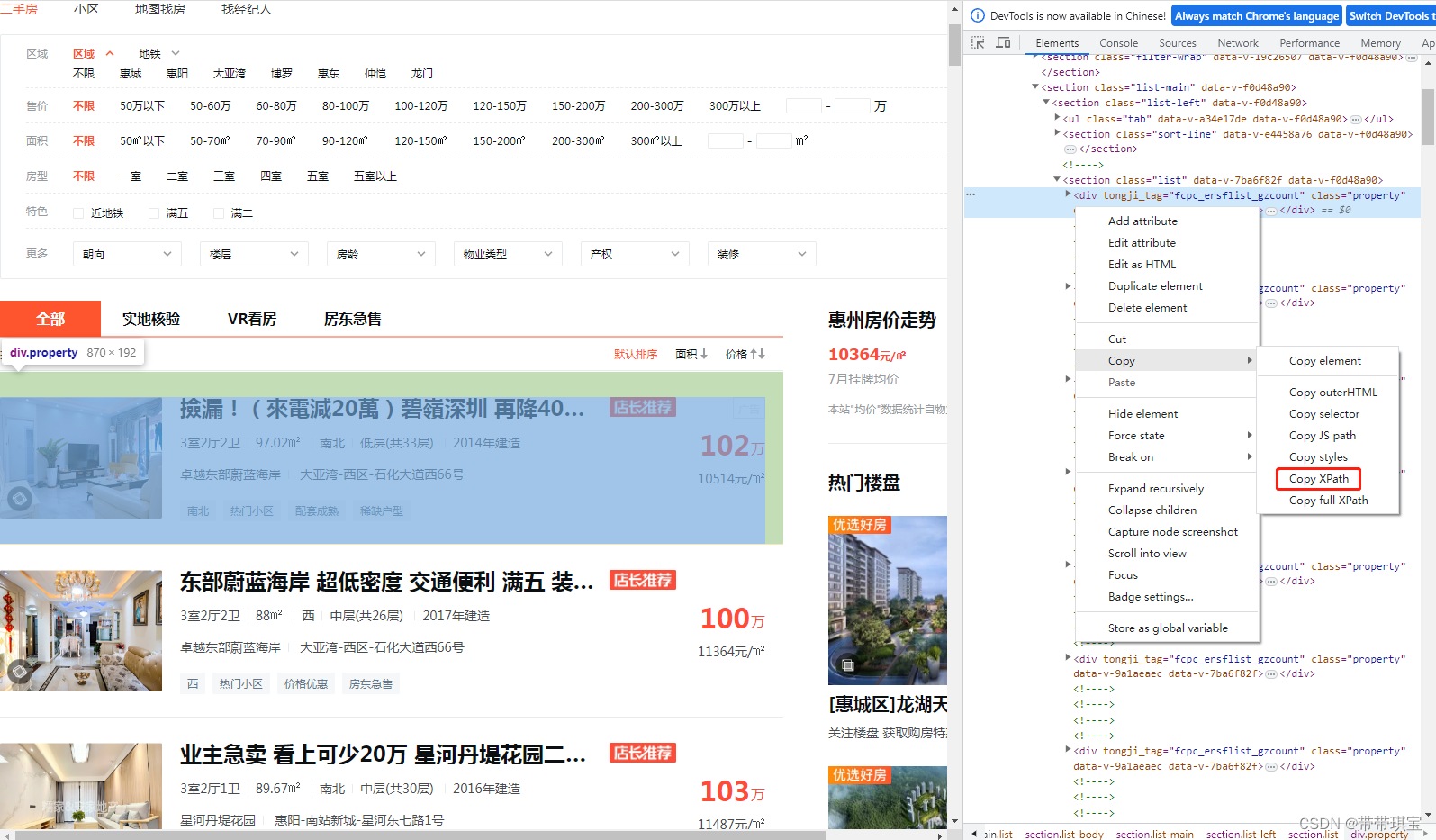
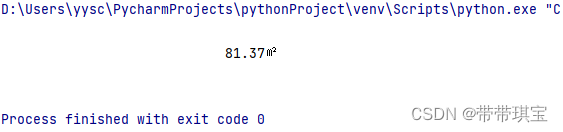
感觉Xpath的灵魂在于可以直接一键在开发工具里面 copy 这次与之前不同,因为这个网站访问太频繁总是需要手动去验证,所以怕爬取数据不全或被封IP,所以适当用了一点点反爬机制 import requests from lxml import etree # etree 才有xpath的功能 import random import time # 用两个设备去访问 user_agent_list=['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'] # 指定UA head={'user-agent':random.sample(user_agent_list,1)[0]} # 网页的参数似乎是动态的,几次打开网页参数都不相同,所以用random随机生成一下 # 同时可以用于随机休眠 num=random.randint(1,15) # 指定 URL url='https://huizhou.58.com/ershoufang/?PGTID=0d100000-002d-2a8b-790f-e8341946c3e9&ClickID=%d' r_url=url%num # 获取响应数据 response=requests.get(r_url,headers=head).text # 准备一个etree将html源码加载到里面去 tree=etree.HTML(response)当前页面一个个房源信息的路径: tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div'写出第一个房源的信息:(对于标记第一个房源信息的 div 标签,可以去掉[1]获得当页所有div列表用来遍历)这里的 [0] 是因为返回的是列表,我们要取里面的字符串 # 先写出第一个房源的信息 title=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/div[1]/h3/text()')[0] structure=''.join(tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[1]/p[1]/span/text()')) # 使用''连接字符串的每个字符 square=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[1]/p[2]/text()')[0].strip() # 使用strip去除两端空格 house_name=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[2]/p[1]/text()')[0] place='-'.join(tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[2]/p[2]/span/text()')) detail='/'.join(tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[3]/span/text()')) total_price=''.join(tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[2]/p[1]/span/text()')) avg_price=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[2]/p[2]/text()')[0]输出验证: 东部蔚蓝海岸 配套齐全 正南朝向 交通便捷 有电梯 3室2厅2卫 97㎡ 卓越东部蔚蓝海岸 大亚湾-西区-石化大道西66号 南/满五年 106万 10928元/㎡没什么大问题,进行循环: 进行循环遍历,用d遍历所有div标签,以div标签作为当前节点 ./ 往下找 div_list=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div') for d in div_list: title = d.xpath('./a/div[2]/div[1]/div[1]/h3/text()')[0] structure = ''.join(d.xpath('./a/div[2]/div[1]/section/div[1]/p[1]/span/text()')) # 使用''连接字符串的每个字符 square = d.xpath('./a/div[2]/div[1]/section/div[1]/p[2]/text()')[0].strip() # 使用strip去除两端空格 house_name = d.xpath('./a/div[2]/div[1]/section/div[2]/p[1]/text()')[0] place = '-'.join(d.xpath('./a/div[2]/div[1]/section/div[2]/p[2]/span/text()')) detail = '/'.join(d.xpath('./a/div[2]/div[1]/section/div[3]/span/text()')) total_price = ''.join(d.xpath('./a/div[2]/div[2]/p[1]/span/text()')) avg_price = d.xpath('./a/div[2]/div[2]/p[2]/text()')[0] print(title,structure,square,house_name,place,detail,total_price,avg_price) # 随机休眠 time.sleep(num)成功获得数据,并且是齐全的  (二)补充 (二)补充
这个程序只会获取第一页数据,在URL里面有页面参数,要获取更多只需要通过字符处理然后嵌套一层循环就可以了 此外,该网站url还有一个PGTID参数也是动态的,比如我第二天用原来的URL访问,就又会不成功了,所以这种动态的网页还不知道要怎么处理 (三)过程中一些值得记录的处理1、''.join('str')
会出现如下结果,需要进行字符串的拼接,所有字符都是我们需要的,直接用''.join('str') structure=''.join(d.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/section/div[1]/p[1]/span/text()')[0]) # 使用''连接字符串的每个字符
python学习之把列表元素拼接成字符串的4种方法_python列表拼接成字符串_逃逸的卡路里的博客-CSDN博客 此处必须要定位到标签!!定位到 标签返回空字符串,因为字符是存在 span 里面的 2、'str'.strip()
出现了很多空格 使用 strip() 函数去除两端空格,或者正则提取非空格文本,最开始我是用 isspace() 函数判断逐一输出的,实在有呆- - 3、time、random 模块的反爬 使用了 time.sleep()、random.sample()(这个函数运行时Python警告可能会在后续版本删除)、random.int()几个函数进行随机休眠和UA 伪装 三、代码 import requests from lxml import etree # etree 才有xpath的功能 import random import time user_agent_list=['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'] head={'user-agent':random.sample(user_agent_list,1)[0]} num=random.randint(1,15) url='https://huizhou.58.com/ershoufang/?PGTID=0d100000-002d-2a8b-790f-e8341946c3e9&ClickID=%d' r_url=url%num response=requests.get(r_url,headers=head).text # 准备一个etree将html源码加载到里面去 tree=etree.HTML(response) div_list=tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div') for page in range(5): for d in div_list: title = d.xpath('./a/div[2]/div[1]/div[1]/h3/text()')[0] structure = ''.join(d.xpath('./a/div[2]/div[1]/section/div[1]/p[1]/span/text()')) # 使用''连接字符串的每个字符 square = d.xpath('./a/div[2]/div[1]/section/div[1]/p[2]/text()')[0].strip() # 使用strip去除两端空格 house_name = d.xpath('./a/div[2]/div[1]/section/div[2]/p[1]/text()')[0] place = '-'.join(d.xpath('./a/div[2]/div[1]/section/div[2]/p[2]/span/text()')) detail = '/'.join(d.xpath('./a/div[2]/div[1]/section/div[3]/span/text()')) total_price = ''.join(d.xpath('./a/div[2]/div[2]/p[1]/span/text()')) avg_price = d.xpath('./a/div[2]/div[2]/p[2]/text()')[0] print(title,structure,square,house_name,place,detail,total_price,avg_price) time.sleep(num) |

【本文地址】
今日新闻 |
推荐新闻 |